Prévision de Stock Multi-Secteurs avec le Machine Learning
Dans ce projet, je développe une solution complète de machine learning, notamment des modèles de prévision de stocks adaptés aux secteurs du retail, de la pharmacie et du luxe. L’objectif est d’anticiper les ruptures et les surstocks grâce à des algorithmes performants intégrant toutes les étapes, de la préparation des données à la mise en production.
Tout au long de ce projet, j’utiliserai l’approche par Programmation Orientée objet (POO). Tout simplement par ce que la structure du code, le rend plus modulaire et facilite la maintenance, un atout clé pour les projets de machine learning en production.
Pourquoi avoir utilisé l’approche par POO dans ce projet ?
1 – Modularité et réutilisabilité
Les classes permettent d’encapsuler des concepts réutilisables, comme un modèle de ML, un préprocesseur de données ou une stratégie d’entraînement.
Exemple : Une classe ModelTrainer peut être réutilisée pour plusieurs modèles sans réécrire le code.
2 – Meilleure organisation du code
En séparant les responsabilités dans différentes classes (ex: DataLoader, FeatureExtractor, MLModel), le code devient plus clair et facile à naviguer.
3 – Facilité de maintenance et d’extension
Si tu ouhaites changer l’algorithme d’apprentissage ou ajouter une nouvelle méthode d’optimisation, tu peux simplement hériter d’une classe existante sans perturber le reste du code.
4 – Encapsulation et abstraction
Tu peux cacher les détails internes du modèle (comme l’optimiseur ou la gestion des données) derrière des méthodes simples comme train() ou predict(), ce qui facilite l’utilisation du code.
5 – Polymorphisme et flexibilité
Avec l’héritage et les classes abstraites, tu peux définir une interface commune pour plusieurs types de modèles (RandomForestModel, NeuralNetworkModel, etc.), ce qui facilite l’intégration et l’expérimentation.
Objectif de l’outil développé
L’outil que je cherche à développer basé sur un algorithme générique pourrait être utile dans des secteurs aussi variés que le retail, la pharmacie, ou des entreprises comme L’Oréal, où la gestion des stocks est cruciale pour optimiser les approvisionnements, réduire les coûts et améliorer l’efficacité des opérations.
Valeurs ajoutées de la solution
- Optimisation de la gestion des stocks : La gestion des stocks est un domaine clé pour de nombreuses entreprises, et une prévision de stock plus précise peut aider à mieux gérer la demande, réduire le gaspillage, éviter les ruptures de stock et minimiser les coûts d’entreposage.
- Réduction des coûts : Une bonne prévision des stocks permet de réduire les coûts liés aux excédents de stock (gaspillage, stockage inutile) tout en assurant que la demande soit satisfaite à temps.
- Généralisation de l’outil : En développant un algorithme générique, vous créez un produit qui peut s’adapter à différents secteurs avec peu de modifications. Un tel outil pourrait être utilisé dans :
-
- Retail : Prévision des ventes et des stocks de produits pour les grandes surfaces, les magasins en ligne, etc.
- Pharmacie : Prévision des stocks de médicaments en fonction de la demande saisonnière, des prescriptions, des tendances de consommation.
- Industrie cosmétique (L’Oréal, etc.) : Prévision des stocks pour les produits de beauté, les accessoires, etc.
Techniques de ML utilisées
Pour mener à bien ce projet, j’utilise des techniques avancées de machine learning qui consiste à appliquer des modèles de machine learning comme les réseaux de neurones récurrents (RNN), l’ARIMA, ou XGBoost pour prévoir la demande en fonction des historiques de ventes, des promotions, des saisons, etc.
La solution développée pourrait par la suite être intégrée dans différents systèmes : Ce type d’outil, une fois développé, pourrait être intégré dans des ERP (Enterprise Resource Planning) ou des systèmes de gestion de la chaîne d’approvisionnement utilisés par différentes industries, augmentant ainsi sa portée.
Structuration du code
Avant toute chose, j’ai défini la structure de mon code pour le rendre maintenable et lisibilité.
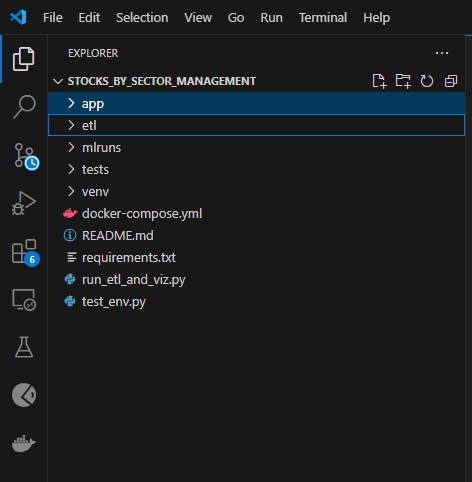
Structure globale du code
La première image montre la structure globale de mon code développé dans vscode. on peut voir que le travail est organisé de la façon suivante :
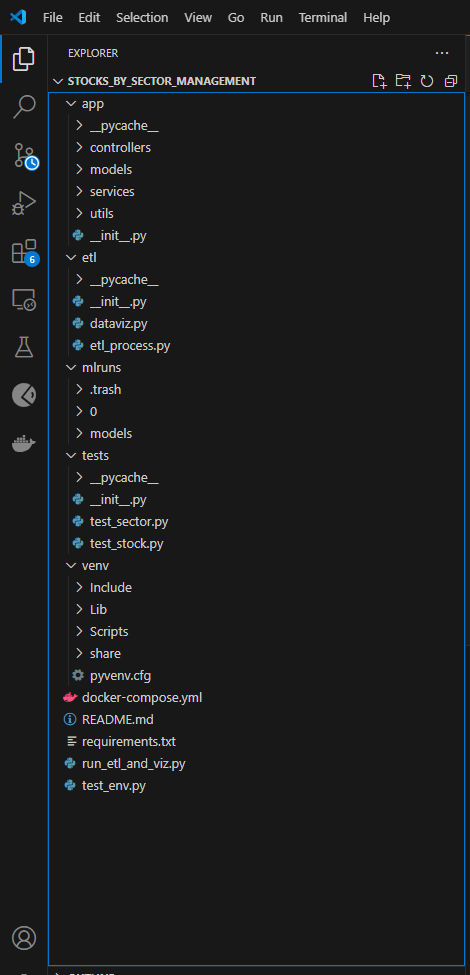
Structure détaillée du code
app/ : contient la logique principale de l’application avec des sous-dossiers pour les contrôleurs, modèles, services et utilitaires.
etl/ : responsable du processus d’ETL avec des fichiers comme etl_process.py et dataviz.py.
mlruns/ : est utilisé pour suivre des expérimentations en ML, probablement avec MLflow.
tests/ : dédié aux tests unitaires, avec des fichiers comme test_sector.py et test_stock.py.
venv/ : Environnement virtuel Python contenant les dépendances du projet.
On retrouve également quelques fichiers spécifiques dont :
docker-compose.yml: indique que le projet peut être conteneurisé.requirements.txt: liste des dépendances nécessaires pour exécuter le projet.run_etl_and_viz.py: un script pour exécuter l’ETL et la visualisation.
On y voit une séparation claire entre l’application principale (app), le traitement des données (etl) et les tests (tests). Présence de fichiers essentiels pour la reproductibilité (requirements.txt, docker-compose.yml). Utilisation d’un dossier mlruns, qui laisse penser que vous utilisez un suivi d’expériences.
Que contient chaque dossier ?
Intéressons-nous maintenant au contenu du code. Chaque dossier joue un rôle spécifique dans l’architecture du projet et suit une approche MLOps bien définie.
1. Dossier app/
Contient l’implémentation principale de l’application, avec une architecture MVC (Modèle – Vue – Contrôleur) pour séparer les responsabilités.
📂 controllers/
Gère les interactions entre l’utilisateur et le système.
sector_controller.py: gère les requêtes liées aux secteurs d’activité (retail, pharma, luxe).stock_controller.py: gère les requêtes relatives aux stocks.
Par exemple le script stock_controller.py contient le code suivant :
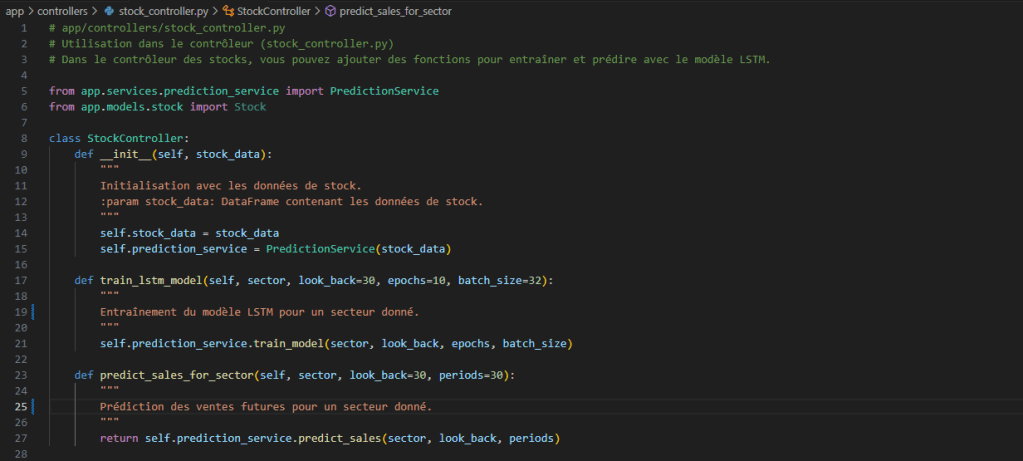
stock_controller.py
📂 models/
Représente les données métiers et la persistance.
sector.py: modélise les secteurs d’activité.stock.py: modélise les stocks disponibles..dvcfiles : suivi des données avec DVC (Data Version Control) pour gérer les versions des fichiers de données.
Le fichier sector.py définit une classe Sector, qui permet de gérer les données spécifiques à un secteur d’activité (pharmacie, luxe, etc.). Il s’agit d’un modèle essentiel pour l’analyse des ventes, la gestion des stocks et la prédiction des tendances par secteur.
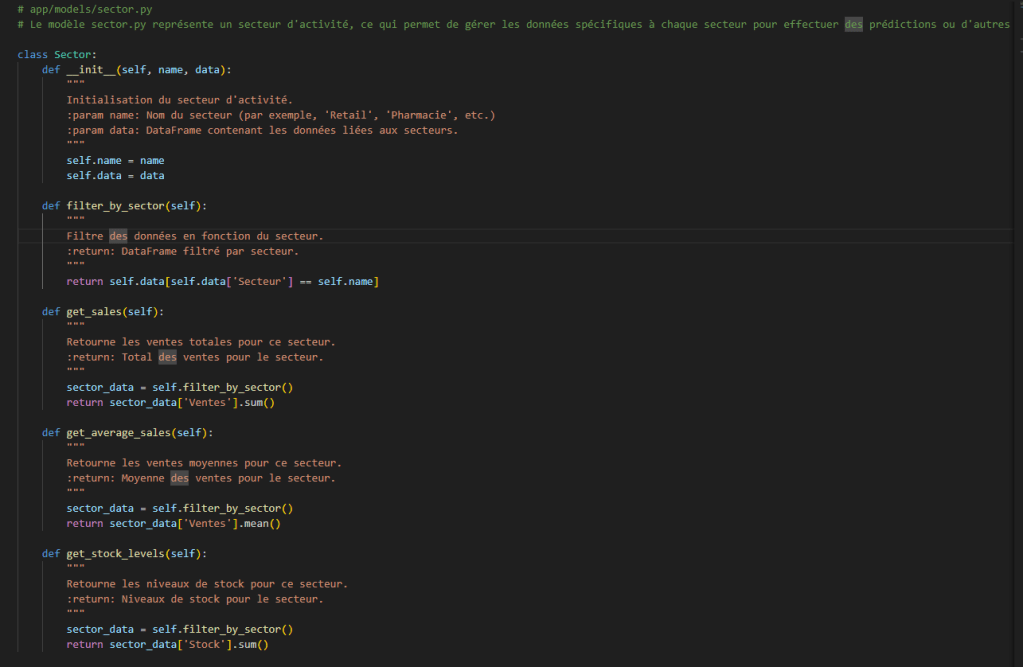
sector.py
Fonctionnalités principales du modèle sector
La classe Sector prend en entrée :
- Un nom de secteur (
name) pour identifier le domaine d’activité (ex : « Retail »). - Un jeu de données (
data), qui est un DataFrame contenant des informations sur les ventes et les stocks.
Elle propose plusieurs méthodes pour analyser ces données :
filter_by_sector(): filtre le DataFrame en fonction du secteur donné.get_sales(): calcule le total des ventes pour ce secteur.get_average_sales(): retourne la moyenne des ventes.get_stock_levels(): retourne le niveau total des stocks.
Le fichier stock.py quant à lui définit la classe Stock, qui prépare les données de stock et de ventes sous forme de séries temporelles pour entraîner un modèle LSTM (Long Short-Term Memory). Le modèle est essentiel pour effectuer des prévisions de ventes par secteur afin d’optimiser la gestion des stocks.
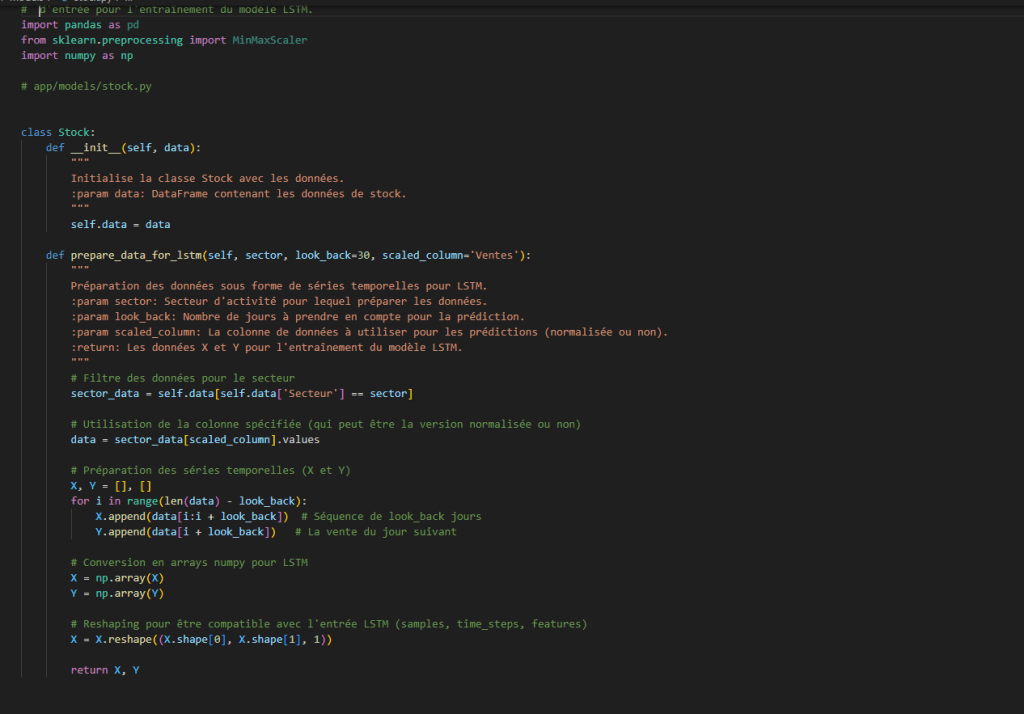
stock.py
Fonctionnalités principales de stock
La classe Stock prend en entrée :
- Un jeu de données (
data), sous forme de DataFrame, contenant des informations sur les ventes et les stocks.
Elle propose une méthode clé :
prepare_data_for_lstm(sector, look_back=30, scaled_column='Ventes')- filtre les données par secteur d’activité (ex: Retail, Pharmacie, Luxe).
- crée des séquences temporelles sur une période définie (
look_back). - génère des jeux de données
XetYpour entraîner un LSTM :X: Séquences des 30 derniers jours.Y: Valeur cible (vente du jour suivant).
- reshape les données pour être compatibles avec un réseau LSTM.
📂 services/
Contient la logique métier et les fonctionnalités de prédiction.
prediction_service.py: Implémente les modèles de machine learning pour prédire la demande de stock.stock_controller.py: Service complémentaire pour gérer les opérations stock.
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
import mlflow
import mlflow.keras
from app.models.stock import Stock
class PredictionService:
def __init__(self, stock_data):
"""
Initialisation du service de prédiction avec les données de stock.
:param stock_data: DataFrame contenant les données des stocks.
"""
self.stock_data = stock_data
self.model = None
self.scaler = MinMaxScaler() # Scaler pour normaliser les données
def create_lstm_model(self, look_back=30):
"""
Création du modèle LSTM pour prédire les ventes.
:param look_back: Nombre de jours à prendre en compte pour la prédiction.
:return: Le modèle LSTM créé.
"""
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(look_back, 1))) # 50 unités, séquence
model.add(LSTM(units=50, return_sequences=False)) # 50 unités, pas de séquence de sortie
model.add(Dense(units=1)) # Une sortie (la vente du jour suivant)
model.compile(optimizer='adam', loss='mean_squared_error')
return model
def train_model(self, sector, look_back=30, epochs=10, batch_size=32):
"""
Entraînement du modèle LSTM pour prédire les ventes.
:param sector: Secteur d'activité pour lequel entraîner le modèle.
:param look_back: Nombre de jours pour les séquences d'entrée.
:param epochs: Nombre d'époques pour l'entraînement.
:param batch_size: Taille du batch pour l'entraînement.
"""
# Préparation des données sous forme de séries temporelles pour LSTM
stock = Stock(self.stock_data)
# Extraction et normalisation des données pour le secteur
sector_data = self.stock_data[self.stock_data['Secteur'] == sector]
sales = sector_data['Ventes'].values.reshape(-1, 1) # Conversion en 2D
sales_scaled = self.scaler.fit_transform(sales) # Mise à l'échelle
# Remplacement des ventes normalisées dans les données stock
self.stock_data.loc[self.stock_data['Secteur'] == sector, 'Ventes_scaled'] = sales_scaled.flatten()
# Préparation des séries pour LSTM
X, Y = stock.prepare_data_for_lstm(sector, look_back, scaled_column='Ventes_scaled')
# Création du modèle LSTM
self.model = self.create_lstm_model(look_back)
# Démarrage d'un run dans MLflow
with mlflow.start_run():
# Log des paramètres d'entraînement dans MLflow
mlflow.log_param("sector", sector)
mlflow.log_param("look_back", look_back)
mlflow.log_param("epochs", epochs)
mlflow.log_param("batch_size", batch_size)
# Callback pour enregistrer les métriques dans MLflow
class MLflowCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
if logs:
# Log la perte dans MLflow
mlflow.log_metric("loss", logs.get("loss"), step=epoch)
# Entraînement du modèle avec le callback MLflow
self.model.fit(X, Y, epochs=epochs, batch_size=batch_size, callbacks=[MLflowCallback()])
# Log du modèle avec MLflow
mlflow.keras.log_model(self.model, "lstm_model")
def predict_sales(self, sector, look_back=30, periods=30):
"""
Prédiction des ventes futures pour un secteur donné.
:param sector: Secteur d'activité pour lequel prédire les ventes.
:param look_back: Nombre de jours pour les séquences d'entrée.
:param periods: Nombre de jours à prédire.
:return: Prévisions des ventes futures.
"""
# Préparation des données pour les prévisions
stock = Stock(self.stock_data)
# Extraction des données normalisées pour le secteur
sector_data = self.stock_data[self.stock_data['Secteur'] == sector]
sales = sector_data['Ventes'].values.reshape(-1, 1) # Conversion en 2D
sales_scaled = self.scaler.transform(sales) # Mise à l'échelle
# Préparation des séries pour LSTM
X, _ = stock.prepare_data_for_lstm(sector, look_back, scaled_column='Ventes_scaled')
# Utilisation des dernières données pour prédire les périodes futures
last_data = sales_scaled[-look_back:].reshape(1, look_back, 1)
forecast_scaled = self.model.predict(last_data)
# Retour des prévisions à leur échelle originale
forecast = self.scaler.inverse_transform(forecast_scaled)
return forecast
Ce code définit un service de prédiction basé sur un modèle LSTM (PredictionService) qui entraîne un réseau de neurones récurrent pour prédire les ventes futures par secteur d’activité, en utilisant MLflow pour le suivi des expériences et la journalisation des modèles.
📂 utils/
Contient des outils génériques pour toute l’application.
database.py: gère la connexion et les requêtes vers la base de données.logger.py: met en place un système de logging pour suivre l’activité du projet.
2. Dossier etl/
Contient le pipeline ETL pour préparer et analyser les données.
etl_process.py: automatisation du processus ETL.dataviz.py: contient des scripts pour visualiser les données et insights.
Voir https://charlottebimou-datascientist.fr/2025/01/21/data-analyse-bi/ pour plus de détails.
3. Dossier tests/
Contient les tests unitaires et d’intégration.
test_sector.py: vérifie le bon fonctionnement du module sector.test_stock.py: vérifie le bon fonctionnement du module stock.test_env.py: vérifie la bonne configuration des dépendances et environnements (pas besoin d’être gardé)
4. Dossier venv/
Contient l’environnement virtuel Python avec toutes les dépendances du projet.
Fichiers importants
run_etl_and_viz.py : exécute le pipeline ETL + Visualisation en un seul script.
requirements.txt : liste des bibliothèques Python utilisées (ML, API, ETL).
